Luennot viikolla 6
8-10.2.2000
Ohjelmatiedosto /p/edu/mat-1.414/maple/ohjelmat.mpl
Kun koodeja kertyy, niitð kannattaa kerðtð tekstitiesostoon, jonka voi lukea Mapleen. komennolla:
>
read("../v2/ohjelmat.mpl");
![]()
![]()
![]()
![]()
![]()
![]()
> op(lag);
![]()
![]()
![]()
![]()
![]()
![]()
Diskretointiapufunktio:
Mikððn ei meitð estð mððrittelemðstð Matlabista tuttua linspace-funktiota: (Otamme Maplessa oletukseksi 10.)
> op(linspace);
![]()
![]()
![]()
![]()
>
Interpolointivirhe voidaan ohjelmoida funktioksi, jolle annetaan interpoloitavan funktion lauseke ja interpolointipisteet sekð
symboli, jolla muuttujaa merkitððn. Otetaan globaali symboli
![]() samaan rooliin, jossa se aina on.
samaan rooliin, jossa se aina on.
> op(interR);
![[Maple Math]](images/Lv618.gif)
Testataan sitð pienellð esimerkillð: sin-funktion interpolointi pisteissð 0,1,2 .
> interR(sin,[0,1,2],x);
![]()
Kðytt—simerkki oli ty—arkilla Lv5.mws . Tðssð kirjoitimme interR-funktion niin, ettð xd ja x sijoitettiin parametrilistaan, se on toki turvallisempaa ja oikeaoppisempaa ohjelmointia kuin aiempi globaalien suruton viljelytyyli,
Interpolaatioesimerkki (kertausta Lv5:stð)
Kerrataan nyt vielð esimerkki (ei tatrvitse katsoa, jos kyllðstyttðð)
> xd:=[9.0,9.5,10.0,11.0];yd:=map(ln,xd);
![]()
![]()
> L:=lag(xd,x);
![]()
![]()
![]()
![]()
> p:='sum(yd[j]*L[j],j=1..4)';
![[Maple Math]](images/Lv626.gif)
> p:=eval(p);
![]()
![]()
![]()
![]()
Mððritellððn polynomilauseke funktioksi :
> pf:=unapply(p,x):
> map(pf,xd);
![]()
> yd;
![]()
Kunnossa on.
> with(plots):
> pisteet:=zip((x,y)->[x,y],xd,yd);
![]()
Kenties helpommin ymmðrrettðvð tapa:
> # pisteet:=[seq([xd[i],yd[i]],i=1..4)];
>
xykuva:=plot(pisteet,x=8.5..11.5,style=point,symbol=circle):
> ln_ja_p:=plot([ln(x),p],x=8.5..11.5,color=[blue,grey]):
> display([xykuva,ln_ja_p]);
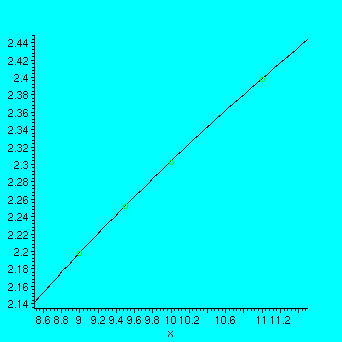
> plot(ln(x)-p,x=8.5..11.5);
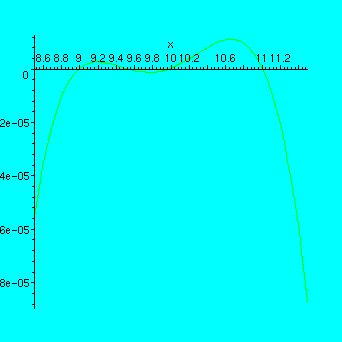
> p;
![]()
![]()
![]()
![]()
> pf(10.5);
![]()
> ln(10.5);
![]()
> virhe:=interR(ln,xd,x);
![[Maple Math]](images/Lv642.gif)
Pienenevðlle funktiolle saadaan ylðraja laskemalla arvo vasemmassa pððtepisteessð.
> maxvirhe:=subs(xi=xd[1],virhe);
![]()
> subs(x=10.5,maxvirhe);
![]()
> ln(10.5)-pf(10.5);
![]()
> %%-%;
![]()
Max-virhe koko vðlillð
Ylðraja max-virheelle koko vðlillð
Tulotermin max saadaan derivoimalla, laskemalla derivaatan 0-kohdat ja laskemalla
arvo niissð sekð pððtepisteissð, niitð sitten verrataan.
> dmaxv:=diff(maxvirhe,x);
![]()
![]()
> dernolla:=solve(dmaxv=0,x);
![]()
> maxvf:=unapply(maxvirhe,x);
![]()
Periaatteessa pitðisi katsoa derivaatan 0-kohdat ja pððtepisteet, kuten alla tehdððn. Nyt kyllð tiedetððn, ettð pððtepisteissð
virhe on 0, koska niissð interpoloidaan. Olkoon siis yleisen funktion maksimointitilanteen mukaisesti:
> map(abs@maxvf,[xd[1],dernolla,xd[4]]);
![]()
> maxvirhe:=max(op(%));
![]()
Katsotaan vielð kuvaa:
> plot(ln(x)-p,x=9..11);
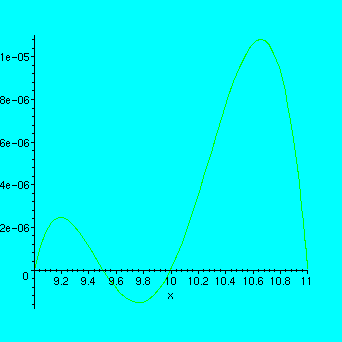
Tðssð tapauksessa virhearvio oli varsin tarkka.
Kuvaa klikkaamalla nðhdððn, ettð todellinen maxvirhe on n.
![[Maple Math]](images/Lv654.gif) .
.
Splinit
> readlib(spline):
> f:=x->1/(1+25*x^2):
> n:=4:xd:=linspace(-1,1,n);
> yd:=map(f,xd);
> s:=spline(xd,yd,x);
> plot([f(x),s],x=-1..1);
> plot(f(x)-s,x=-1..1);
![]()
![]()
![[Maple Math]](images/Lv657.gif)
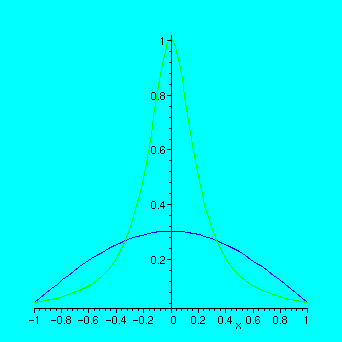
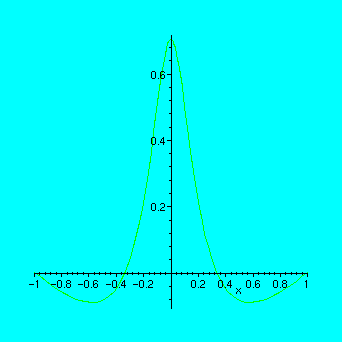
>
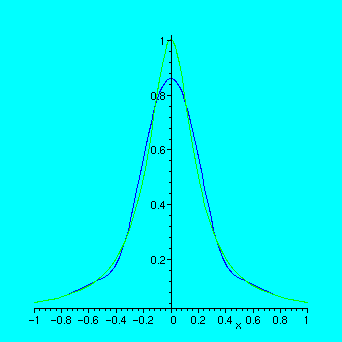
n:=10:xd:=linspace(-1,1,n);
yd:=map(f,xd);
s:=spline(xd,yd,x):
plot([f(x),s],x=-1..1);
plot(f(x)-s,x=-1..1);
![]()
![]()
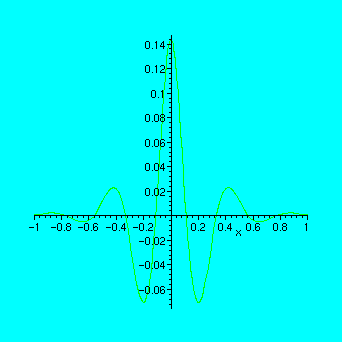
Numeerinen integrointi
> restart:read("/home/apiola/opetus/peruskurssi/v2-3/maple/ohjelmat.mpl");
![]()
![]()
![]()
![]()
![]()
![]()
Mððrittelimme funktiot trapetsi ja simpsoni. Lisðksi student :ssa on trapezoid ja simpson , mutta ilman virhetermið. Muuten ne ovat yhdenmukaiset int -funktion kanssa, mikð on kaunista.
> op(trapetsi);op(simpsoni);print(simpsonvirhe);
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
> with(student);
![]()
![]()
![]()
Katsotaan vielð esimerkkinð integraalin
![[Maple Math]](images/Lv689.gif) laskemista trapetsilla + virhearviota.
laskemista trapetsilla + virhearviota.
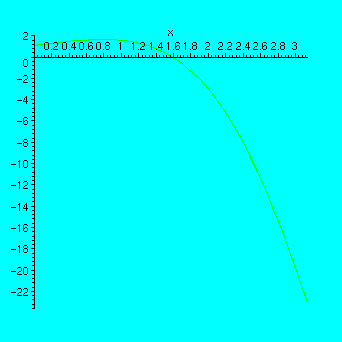
> f:=x->exp(x)*cos(x);plot(f(x),x=0..Pi);
![]()
> SR:=trapetsi(f,0,Pi,10);
![]()
> S:=SR[1];R:=SR[2];
![]()
![]()
> plot(abs(R),xi=0..Pi,thickness=2);
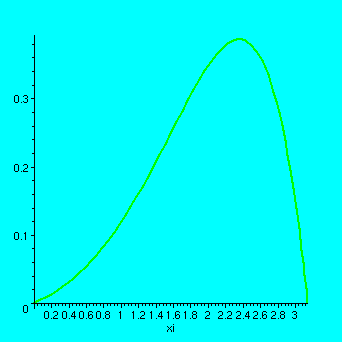
> maxvirhe:=0.4;
![]()
> maxsuhtvirhe:=maxvirhe/abs(S);
![]()
>
Trapetsin ja Simpsonin vertailua
Lasketaan yksi esimerkki, joka nðyttðð laskentat—iden suuruusluokkavertailun.
> Isi:=Int(sin(x),x=0..Pi);tol:=2*10^(-5);
![[Maple Math]](images/Lv698.gif)
![]()
>
n:='n':tol:='tol':trapetsivirhe(sin,0,Pi,n);Mtr:=eval(subs(xi=Pi/2,%));
simpsonvirhe(sin,0,Pi,n):Ms:=abs(eval(subs(xi=Pi/2,%)));
![[Maple Math]](images/Lv6100.gif)
![[Maple Math]](images/Lv6101.gif)
![[Maple Math]](images/Lv6102.gif)
> ntr:=solve(Mtr=tol,n)[1];ns:=solve(Ms=tol,n)[1];
![]()
![[Maple Math]](images/Lv6104.gif)
> evalf(subs(tol=2*10^(-5),ntr));evalf(subs(tol=2*10^(-5),ns));
![]()
![]()
Siis t rapetsilla tarvitaan 360 osavðlið ja Simpsonilla riittðð 18 ! (Muista, oltava parillinen)
Lasketaan kolme integraalia molemmilla menetelmillð ja katsotaan, miten virhe kðyttðytyy askelpituuden funktiona. Kðytðmme virheenð oikeaa virhettð, emme tðssð selvittele virheen arvioimista jððnn—stermillð, vaan oikean virheen kðyttðytymistð.
>
I1:=Int(exp(-x^2),x=0..1)=int(exp(-x^2),x=0..1);
I2:=4*Int(1/(1+x^2),x=0..1)=4*int(1/(1+x^2),x=0..1);
I3:=Int(1/(2+cos(x)),x=0..2*Pi)=int(1/(2+cos(x)),x=0..2*Pi);
![[Maple Math]](images/Lv6107.gif)
![[Maple Math]](images/Lv6108.gif)
![[Maple Math]](images/Lv6109.gif)
> f1:=x->exp(-x^2);f2:=x->4/(1+x^2);f3:=x->1/(2+cos(x));
![]()
![[Maple Math]](images/Lv6111.gif)
![]()
> N:=8:
>
trapS1:=seq(trapetsi(f1,0,1,2^k)[1],k=1..N);
tarkka1:=evalf(lhs(I1));trapV1:=seq(tarkka1-trapS1[i],i=1..N);
> tsuhteet1:=seq(trapV1[i]/trapV1[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
![]()
Tðmð on hyvin sopusoinnussa trapetsivirheen O(h^2); - kðyttðytymisen kanssa.
>
trapS2:=seq(trapetsi(f2,0,1,2^k)[1],k=1..N);
tarkka2:=evalf(lhs(I2));trapV2:=seq(tarkka2-trapS2[i],i=1..N);tsuhteet2:=seq(trapV2[i]/trapV2[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
>
Digits:=20:trapS3:=seq(trapetsi(f3,0,2*Pi,2^k)[1],k=1..N);
tarkka3:=evalf(lhs(I3));trapV3:=seq(tarkka3-trapS3[i],i=1..N);tsuhteet3:=seq(trapV3[i]/trapV3[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
![]()
![]()
> with(student):trapezoid(f3(x),x=0..2*Pi);evalf(%);
Warning, new definition for D
![[Maple Math]](images/Lv6131.gif)
![]()
> evalf(trapezoid(f3(x),x=0..2*Pi,4));trapetsi(f3,0,2*Pi,4);
![]()
![[Maple Math]](images/Lv6134.gif)
>
Tðmð on hyvin sopusoinnussa trapetsivirheen
![]() - kðyttðytymisen kanssa.
- kðyttðytymisen kanssa.
Entðpð Simpson:
>
Digits:=10:N:=8:simpS1:=seq(simpsoni(f1,0,1,2^k)[1],k=1..N);
tarkka1:=evalf(lhs(I1));simpV1:=seq(tarkka1-simpS1[i],i=1..N);
ssuhteet1:=seq(simpV1[i]/simpV1[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
Error, division by zero
>
Digits:=20:N:=8:simpS1:=seq(simpsoni(f1,0,1,2^k)[1],k=1..N);
tarkka1:=evalf(lhs(I1));simpV1:=seq(tarkka1-simpS1[i],i=1..N);
ssuhteet1:=seq(simpV1[i]/simpV1[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
![]()
![]()
>
Digits:=10:N:=8:simpS2:=seq(simpsoni(f2,0,1,2^k)[1],k=1..N);
tarkka2:=evalf(lhs(I2));simpV2:=seq(tarkka2-simpS2[i],i=1..N);
ssuhteet2:=seq(simpV2[i]/simpV2[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
Error, division by zero
>
Digits:=20:N:=8:simpS2:=seq(simpsoni(f2,0,1,2^k)[1],k=1..N);
tarkka2:=evalf(lhs(I2));simpV2:=seq(tarkka2-simpS2[i],i=1..N);
ssuhteet2:=seq(simpV2[i]/simpV2[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
![]()
![]()
>
Digits:=10:N:=8:simpS3:=seq(simpsoni(f3,0,2*Pi,2^k)[1],k=1..N);
tarkka3:=evalf(lhs(I3));simpV3:=seq(tarkka3-simpS3[i],i=1..N);
ssuhteet3:=seq(simpV3[i]/simpV3[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
>
Digits:=20:N:=8:simpS3:=seq(simpsoni(f3,0,2*Pi,2^k)[1],k=1..N);
tarkka3:=evalf(lhs(I3));simpV3:=seq(tarkka3-simpS3[i],i=1..N);
ssuhteet3:=seq(simpV3[i]/simpV3[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
Error, division by zero
>
Digits:=50:N:=8:simpS3:=seq(simpsoni(f3,0,2*Pi,2^k)[1],k=1..N);
tarkka3:=evalf(lhs(I3));simpV3:=seq(tarkka3-simpS3[i],i=1..N);
ssuhteet3:=seq(simpV3[i]/simpV3[i+1],i=1..N-1);
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
>
> Digits:=10: # Palataan normaaliin.
Luentotehtðvð: (8.2.)
Gaussin kvadratuuri
> f0:=x->1;f1:=x->x;f2:=x->x^2;f3:=x->x^3;
![]()
![]()
![]()
![]()
> yht0:=int(f0(x),x=-1..1)=c1*f0(x0)+c2*
> f0(x1);
>
yht1:=int(f1(x),x=-1..1)=c1*f1(x0)+c2*f1(x1);
yht2:=int(f2(x),x=-1..1)=c1*f2(x0)+c2*f2(x1);
yht3:=int(f3(x),x=-1..1)=c1*f3(x0)+c2*f3(x1);
>
![]()
![]()
![]()
![]()
> solve({yht0,yht1,yht2,yht3},{x0,x1,c1,c2});
![]()
> allvalues(%);
![]()
Loistavaa!
Korkeamman kertaluvun menetelmissð tarvitaan ortogonaalipolynomeja
with(orthopoly); Legendren polynomit
> with(orthopoly);
Warning, new definition for L
![]()
> P(0,x);P(1,x);P(2,x);
![]()
![]()
![]()
> solve(P(2,x)=0,x);
![]()
Hðmmðstyttðvðð! Jos olisi niin ihmeellisesti, ettð solmut saataisiin Legengden polynomien nollakohtina, niin painokertoimet olisi helppo ratkaista. Niiden suhteenhan yhtðl—systeemi on lineaarinen. Toisaalta ne epðilemðttð saadaan my—s solmuihin liittyvien Lagrangen kertojapolynomien integraaleina. Kumpi on parempi tapa laskea?
Tehtðvð viikolle 7
Moniulotteinen integrointi
Yhteenveto menetelmistð
Tietokonearitmetiikkaa, laskennan tehokkuudesta
Polynomien laskennasta
> p:=-8*x^5+7*x^4-6*x^3-5*x^2-4*x+3;
![]()
> q:=convert(p,horner);
![]()
> with(codegen[cost]):
Warning, new definition for fortran
Warning, new definition for makeproc
> cost(p);cost(q);
![]()
![]()
>
Aritmetiikkaa
> x:=0.57812;q:=x:
![]()
> b[1]:=floor(2*q);q:=frac(2*q);
![]()
![]()
> b[2]:=floor(2*q);q:=frac(2*q);
![]()
![]()
> b[3]:=floor(2*q);q:=frac(2*q);b[4]:=floor(2*q);q:=frac(2*q);
![]()
![]()
![]()
![]()
> b[5]:=floor(2*q);q:=frac(2*q);b[6]:=floor(2*q);q:=frac(2*q);
![]()
![]()
![]()
![]()
> b[7]:=floor(2*q);q:=frac(2*q);b[8]:=floor(2*q);q:=frac(2*q);
![]()
![]()
![]()
![]()
> b[9]:=floor(2*q);q:=frac(2*q);b[10]:=floor(2*q);q:=frac(2*q);
![]()
![]()
![]()
![]()
> b[11]:=floor(2*q);q:=frac(2*q);b[12]:=floor(2*q);q:=frac(2*q);
![]()
![]()
![]()
![]()
> b:='b':
> b:='b':x:=0.578125:q:=x:
> for i from 1 to 30 do b[i]:=floor(2*q);q:=frac(2*q);od: c:=[seq(b[i],i=1..30)];
![]()
![]()
> cc:=append([0],c);
![]()
> polyval0(cc,0.5);
![]()
> polyval([u,v,w],x);
![]()
>
append:=(L1,L2)->[op(L1),op(L2)];
![]()
> Digits:=7:
> a:=10.^15;b:=1;sqrt(a^2+b^2);
>
![]()
![]()
![]()
> Digits:=32:a:=10.^15;b:=1;c:=sqrt(a^2+b^2);
![]()
![]()
![]()
> c;
![]()
> Digits:=20:
> Digits:=5:
> seq([2.^(-j),1.+2^(-j)],j=10..20);
![]()
![]()
![]()
> .49e-4+1.0;
![]()
>
Merkitsevien numeroiden kumoutuminen
> f:=x->x*(sqrt(x+1)-sqrt(x));
![]()
> Digits:=10:
> matrix([seq([10^k,evalf(f(10^k),6),evalf(f(10^k),20)],k=1..6)]);
![[Maple Math]](images/Lv6252.gif)
> Digits:=6:
> x:=100.:sqrt(x+1),sqrt(x);
![]()
> sqrt(x+1)-sqrt(x);
![]()
> Digits:=9:
> x:=100.:sqrt(x+1),sqrt(x);
![]()
>
> sqrt(x+1)-sqrt(x);
>
![]()
6:lla numerolla lasketussa tuloksessa oli vain 3 oikeaa numeroa, 3 alkunumeroa kumoutuivat vðhennyslaskussa ja siten lasku tehtiin vain 3:n numeron tarkkuudella.
Tai ehkð paremmin ilmaistuna: Laskut pitðð suorittaa 3:n lisðnumeron tarkkuudella, jotta tulos on 6:lla numerolla oikein.
Kirjoitetaan kaava muotoon, jossa lavennetaan "liittoluvulla":
> g:=x->x/(sqrt(x+1)+sqrt(x));
![]()
> x:='x':simplify(f(x)-g(x));
![]()
> matrix([seq([10^k,evalf(g(10^k),6),evalf(g(10^k),20)],k=1..6)]);
![[Maple Math]](images/Lv6259.gif)
Nytpð tuli hienosti !
Katsotaanpa Taylorin polynomin laskentaa:
> tayexp:=seq(convert(taylor(exp(x),x=0,j),polynom),j=0..10);
![]()
![]()
![]()
![]()
![]()
> evalf(subs(x=-6.0,[tayexp]),5);exp(-6.);
![]()
![]()
> ykspertayexp:=seq(1/(convert(taylor(exp(x),x=0,j),polynom)),j=1..10);
![[Maple Math]](images/Lv6267.gif)
![[Maple Math]](images/Lv6268.gif)
![[Maple Math]](images/Lv6269.gif)
![[Maple Math]](images/Lv6270.gif)
![[Maple Math]](images/Lv6271.gif)
> evalf(subs(x=6.0,[ykspertayexp]),5);exp(-6.);
![]()
![]()
Mitenkðhðn siinð huonossa ensimmðisessð tavassa lopulta kðy?
> tayexp:=seq(convert(taylor(exp(x),x=0,j),polynom),j=25..30):evalf(subs(x=-6.0,[tayexp]),5);exp(-6.);
![]()
![]()
No on ne nyt sinnepðin, mutta on siinð heittoakin melkoisesti. Ei tunnu uskottavalta, ettð enðð voisi korjaantua.
Alkupððssð lasketaan varsin suuria erimerkkisið arvoja, lopputulos on hyvin pieni. Kun lasketaan kiinteðllð suhteellisella tarkkuudella, niin absoluuttinen virhe tulee suurten termien kohdalla my—s suureksi. Kun lopputulos on pieni, niin sen suhteellinen virhe tulee suureksi. (Pahimmassa tapauksessa isojen termien absoluuttinen virhe voi olla samaa suuruusluokkaa kuin koko lopppusumma, no kaikkihan tietðð, ettei siitð hyvðð seuraa.)
Yleensð, jos lasketaan summaa, jossa on pienið ja suuria positiivisia, niin paras tulos saadaan laskemalla pienimmðstð suurimpaan. (Pðinvastoin laskettaessa pienen termin lisððminen suureen summaan voi hukuttaa pienen kokonaan (vrt. kone-eps).)
>
Epðlineaariset yhtðl—t, Newtonin menetelmð
> f:='f':N:=x->evalf(x-f(x)/D(f)(x)):
> f:=x->x*exp(-x)-abs(sin(10*x));
![]()
> plot(f(x),x=-1..3):
> x1:=(N@@5)(0.25);
![]()
> x1:=(N@@5)(x1);
![]()
> plot(f(x),x=0..0.5):
>